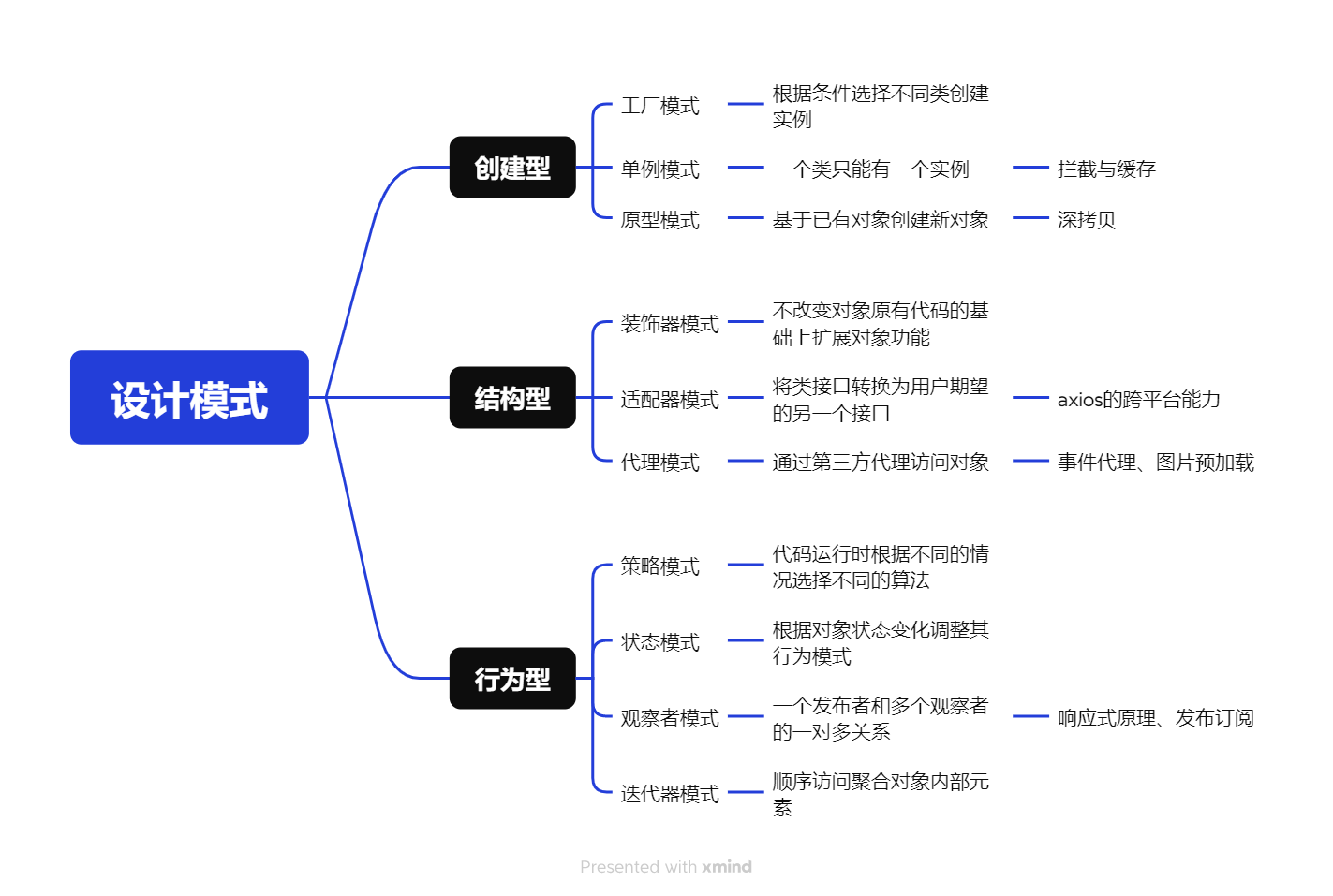
设计模式
# 简介
设计模式是为了解决软件开发过程中出现的常见问题,可以认为是这些常见问题的解决方案。设计模式的核心是区分变与不变,让变化更灵活,让不变更稳定。
# 构造器模式
构造器模式用于解决多个对象实例的变与不变。
构造器模式其实我们几乎每天都在使用。它的一个简单的应用场景就是,假如给一个系统录入用户信息,每个用户都有名字、年龄、职业这三个信息,但是每个信息的值在不同用户之间是不同的。最直接的解决方法就是直接创建用户信息对象
const Jack = {
name: 'Jack',
age: 20,
career: 'student'
}
const Rose = {
name: 'Rose',
age: 28,
career: 'coder'
}
但是如果用户的数量多起来,这样创建用户信息对象的方式就显得笨重而繁琐。使用构造器模式将这个过程中的变与不变进行就能改善这种情况。这个过程中,发生变化的是每个用户,他们的name、age、career的值不同;不变的是每个用户都拥有这三个属性。于是我们可以创建一个构造器用于创建用户信息对象:
function User (name, age, career) {
this.name = name
this.age = age
this.career = career
}
我们创建了一个构造函数帮助我们创建用户信息。变化的部分也即每个用户信息值的不同,我们将其开放给外部,也就是通过函数参数来接收;不变的部分,即每个用户都有的属性,我们将其封装到构造函数内部。这就是构造器模式最简单的例子,实际上就是我们经常使用的用构造函数来创建对象。
有了User这个构造器,我们只需要在数据库中依次读取用户信息并传入构造器就能实现创建所有用户信息对象的需求。
# 工厂模式
构造器模式是为了解决多个对象实例之间的变与不变,而工厂模式是为了解决多个类的变与不变。
# 简单工厂
还是刚才创建用户的问题。现在需求变得复杂,要求根据每个用户的职业不同分配工作,比如学生需要读书考试,程序员需要写代码修bug。最简单的做法就是在原有构造函数的基础上,加一个参数work,来表示用户的工作。但是这样的方法需要在使用构造函数的时候人为区分每个对象的职业,这不符合设计模式的原则。
我们希望到达的效果是,我只需要无脑把参数传递进去,代码能够自动帮助我们区分用户职业并且分配对应的工作。
实际上,每个用户还是有name、age、career这三个属性,因此User构造器是可以保留的。我们要做的,是在调用User创建用户的时候,先区分用户的职业,然后根据职业分配给每个用户工作。
function User (name, age, career, work) {
this.name = name
this.age = age
this.career = career
this.work = work
}
User构造器只是单纯多加一个参数。在User外部再封装一个构造器
function Factory (name, age, career) {
let work
switch (career) {
case 'student':
work = ['学习', '考试']
break
case 'coder':
work = ['写代码', '修bug']
break
// 其它职业的工作分配
}
return new User(name, age, career, work)
}
可以发现,Factory构造器的使用方法和原完全一样。不变的部分依旧是每个用户都拥有四个属性,变化的部分依旧是每个值取值的不同,只是有一个根据用户职业分配工作的逻辑被我们封装到了一个新的Factory构造器中。
工厂模式的目的,总结起来就是为了在使用构造函数的时候能够无脑传递参数。而在需要使用构造函数的地方,就可以考虑到是否可以应用工厂模式。
# 抽象工厂
抽象工厂模式相比简单工厂模式稍微有一些难理解。还是通过例子。假设我要开一个手机制作工厂,一个手机会由操作系统和硬件构成,我不知道具体的手机使用的操作系统和硬件,但是我知道一个手机必须要有这两个部分。因此可以定义一个类:
class MobilePhoneFactory {
createOS () {
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
createHardWare () {
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
}
这就是一个抽象工厂。可以发现抽象工厂中的方法并不能直接调用,因为会报错。抽象工厂是用于定义产品的共性的,它并不负责生产具体的产品。 抽象工厂不创建产品,它负责定义规则,创建产品由具体工厂来实现。
// 具体工厂继承自抽象工厂
class FakeStarFactory extends MobilePhoneFactory {
createOS() {
// 提供安卓系统实例
return new AndroidOS()
}
createHardWare() {
// 提供高通硬件实例
return new QualcommHardWare()
}
}
创建一个继承自抽象工厂的具体工厂,这个工厂内部会对抽象工厂中定义的方法进行具体的实现。调用这个具体工厂类,我们就能得到一个由安卓系统和高通硬件组成的手机。抽象工厂相当于是定义了一个大的框架,但是不负责生产产品。具体工厂继承抽象工厂,即具体工厂生产产品的时候要满足抽象工厂定义的大框架。
再具体一点到操作系统,操作系统包含多个种类,每个操作系统都拥有控制硬件这一个基本功能。因此可以使用一个抽象产品类来对操作系统进行封装。
// 定义操作系统这类产品的抽象产品类
class OS {
controlHardWare() {
throw new Error('抽象产品方法不允许直接调用,你需要将我重写!');
}
}
// 定义具体操作系统的具体产品类
class AndroidOS extends OS {
controlHardWare() {
console.log('我会用安卓的方式去操作硬件')
}
}
class AppleOS extends OS {
controlHardWare() {
console.log('我会用🍎的方式去操作硬件')
}
}
和抽象工厂一样,抽象产品类定义大框架,即每一个操作系统都要有控制硬件的功能,但是它并不负责实现这些功能。具体的控制硬件的方法交给具体产品类来实现。当需要生产一台FakeStar手机的时候
// 这是我的手机
const myPhone = new FakeStarFactory()
// 让它拥有操作系统
const myOS = myPhone.createOS()
// 让它拥有硬件
const myHardWare = myPhone.createHardWare()
// 启动操作系统(输出‘我会用安卓的方式去操作硬件’)
myOS.controlHardWare()
// 唤醒硬件(输出‘我会用高通的方式去运转’)
myHardWare.operateByOrder()
后续如果需求发生变化,比如需要制造新的手机时,只需要定义一个新的具体工厂类即可。同时更改内部的createOS和createHardWare方法就能实现应用不同的硬件和操作系统。
class newStarFactory extends MobilePhoneFactory {
createOS() {
// 操作系统实现代码
}
createHardWare() {
// 硬件实现代码
}
}
最后用一张图片总结一下上面讲的例子:
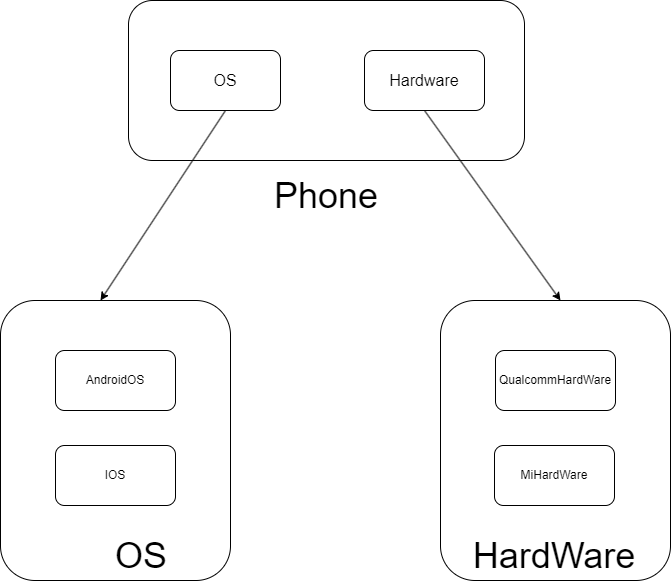
其中Phone表示最高级的抽象工厂,它定义了所有产品的共性,即产品必须具有的功能。OS和HardWare为抽象产品类,它们定义某一个产品必须具有的共性功能,也可以视为一个小型的抽象工厂。
# 单例模式
保证一个类始终只有一个实例,并且提供一个全局的访问点,就是单例模式。
在JavaScript中创建一个类之后,可以通过多次调用new来基于该类创建多个实例,这些实例是独立的,占据单独的内存空间。如果需要实现单例模式,则要求类具有在创建实例时判断自己是否已经被调用过,并且在非首次调用的时候返回首次调用时创建的实例的能力。
class SingDog {
show() {
console.log('我是单例对象')
}
static getInstance() {
// 判断实例是否已经被创建
if (!SingDog.instance) {
SingDog.instance = new SingDog()
}
return SingDog.instance
}
}
单例模式思想的一个典型的生产应用就是Vuex。在一个Vue应用中,始终只会有一个Store实例,不论在哪一个组件当中,访问到的都是唯一的Store。Vuex的源码并没有直接使用单例模式,但是其设计非常符合单例模式的思想,也即拦截和判断。
Vuex创建Store的部分源码,其中并没有上述所说的在类中实现的拦截判断实例是否已经创建的逻辑:
class Store {
constructor (options = {}) {
// ...
this._actions = Object.create(null)
this._mutations = Object.create(null)
this._wrappedGetters = Object.create(null)
this._modulesNamespaceMap = Object.create(null)
this._subscribers = []
this._watcherVM = new Vue()
// 将 this 赋值给 store,这是为了在后续的函数中使用 Store 实例的上下文
const store = this
// 将 this 中的 dispatch 和 commit 方法解构出来,以便在后续的函数中使用
const { dispatch, commit } = this
// 分别为 dispatch 和 commit 方法绑定上下文
this.dispatch = function boundDispatch (type, payload) {
return dispatch.call(store, type, payload)
}
this.commit = function boundCommit (type, payload, options) {
return commit.call(store, type, payload, options)
}
// ...
}
}
实际上,这个拦截的逻辑被放在了Vue.use()方法中,Vuex需要通过Vue.use()方法才能被注入到Vue应用中,而Vue.use()实际上是去调用了在Vuex中实现的install方法:
let Vue // 这个Vue的作用和楼上的instance作用一样
export function install (_Vue) {
// 判断传入的Vue实例对象是否已经被install过Vuex插件(是否有了唯一的 store)
if (Vue && _Vue === Vue) {
if (process.env.NODE_ENV !== 'production') {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
}
return
}
// 若没有,则为这个Vue实例对象install一个唯一的Vuex
Vue = _Vue
// 将Vuex的初始化逻辑写进Vue的钩子函数里
applyMixin(Vue)
}
install方法首先会判断一次传入的Vue实例是否已经有了Store,如果已经存在则会报错,不存在则正常执行安装逻辑。
单例模式的核心思想就是拦截实例的创建操作。在真正进行创建实例的操作前,先判断是否已经存在创建过的实例。同时这也要求,在创建实例的时候需要将实例存储在一个类可以访问到的位置,一般来说就是直接挂到类自身上。
关于单例模式的两道经典面试题:
- 实现一个Storage类,单例模式。
class Storage {
static getInstance() {
if (!Storage.instance) {
Storage.instance = new Storage()
}
return Storage.instance
}
get(key) {
return localStorage.getItem(key)
}
set(key, value) {
return localStorage.setItem(key, value)
}
}
- 实现一个全局的模态框。
// 闭包的方式实现
const Modal = (function () {
let modal = null
return function () {
if (!modal) {
modal = document.createElement('div')
modal.innerHTML = '我是一个全局唯一的Modal'
modal.id = 'modal'
modal.style.display = 'none'
document.body.appendChild(modal)
}
return modal
}
})()
# 原型模式
在创建对象时,先找到一个对象作为原型,然后通过克隆原型对象的方式创建一个与原型一样的对象,新对象和原型对象公用一套数据和方法,这样的模式称为原型模式。原型模式不仅是一种设计模式,更是一种编程范式。 原型模式的核心思想是基于现有对象的属性和方法创建新对象,而无需显式调用类或构造函数。
JavaScript中的Object.create()方法是原型模式的天然实现,该方法可以创建一个以指定对象为原型的新对象。需要注意的是,JavaScript中的原型模式和强类型语言(比如Java)中的原型模式是有一定区别的,JavaScript中都是基于原型和原型链来实现的,强类型语言则是通过类来实现。JavaScript中的class并非真正的类,它只是原型继承的一种语法糖而已。
面试中经常问到的“实现Java中的克隆模式”或者“使用JavaScript实现原型模式”等问题,实际上是为了考察我们对于原型模式的理解是否到位,即基于现有对象创建新对象。这类问题有一个更加好懂的提问方式,使用JavaScript实现对象的深拷贝。关于对象深拷贝,可以参考这篇博客 (opens new window)。
# 装饰器模式
装饰器模式其实跟ES7中实现的装饰器一样,目的是在不修改原有对象代码的基础上,拓展对象的功能。
不关注原有逻辑,只关注拓展功能是装饰器模式的核心所在。实际业务开发中在对原有功能进行迭代的时候,装饰器模式非常有用。因为原有功能的逻辑可能是由其他人甚至已经离职的同事编写的,如果需要修改原有代码来实现新功能,就要求我们需要首先理解原有功能的实现逻辑,这是非常费时并且不明智的做法。借助装饰器模式的思想,我们不关注原有功能如何实现,只关心我们需要拓展的新功能。
假设现在有一个原始的车辆类:
class Car {
constructor() {
this.description = "Basic car";
}
getDescription() {
return this.description;
}
}
现在我们希望给车辆增加导航功能和跑车外观。最直接的想法是直接在原有的车辆类内部增加新的方法即可,但是如果这个车辆类是一个迭代了非常久的功能,内部的代码实现非常复杂,直接去修改源代码并不明智。借助装饰器模式,我们定义两个装饰器函数:
function addNavigation(car) {
car.getDescription = function() {
return car.getDescription() + ', with navigation';
};
return car;
}
function addSportsAppearance(car) {
car.getDescription = function() {
return car.getDescription() + ', with sports appearance';
};
return car;
}
接下来,如果我们需要给车添加这些功能,则直接将装饰器函数应用到车辆类的实例即可。
let myCar = new Car();
myCar = addNavigation(myCar);
myCar = addSportsAppearance(myCar);
console.log(myCar.getDescription()); // 输出:Basic car, with navigation, with sports appearance
前面说过目前ES已经原生支持装饰器语法了,详细的介绍可以看阮一峰老师的ES6教程 (opens new window)。
装饰器模式一个非常经典的生产应用场景就是React的高阶组件。高阶组件本质上是一个函数,接收一个组件作为参数,返回一个经过改造后的组件。高阶组件并不改变原有组件的代码,同时可以对原组件的功能进行扩展。
# 适配器模式
适配器模式把一个类的接口转换为用户所期望的另一个接口。
适配器模式其实类似于现实生活中转接线的作用。比如我现在有一条TypeC的数据线,但是电脑只有一个USB的A口。这个时候我们可以买一条转接线,一端通过USB的A口连接电脑,另一端通过TypeC口连接我们的数据线。这里的转接线就是一个适配器。可以说,他把电脑(类)的USB的A口(原有接口)转换为我们需要的TypeC接口(用户期望的接口)。
一个简单的例子,现在fetch方法因为其简单快速的请求特性,非常受欢迎。所以公司的程序员小王封装了一个基于fetch网络请求库。
class HttpUtils {
static get (url) {
return new Promise((resolve, reject) => {
fetch(url)
.then(reponse => reponse.json())
.then(result => resolve(result))
.catch(error => reject(error))
})
}
static post (url) {
return new Promise((resolve, reject) => {
fetch(url, {
method: 'POST',
headers: {
Accept: 'application/json',
'Content-Type': 'application/x-www-form-urlencoded'
},
body: {}
})
.then(response => response.json())
.then(result => {
resolve(result)
})
.catch(error => {
reject(error)
})
})
}
}
这个网络请求库只需要在使用的时候传递url以及body参数就可以了。老板觉得小王干的不错,所以交给小王一个艰巨的任务,把公司所有的项目网络请求都使用fetch来完成。小王傻了,因为公司有很多的老项目都是使用XMLHttpRequest来完成的,这些请求调用时需要传递参数是这样的:
function Ajax(type, url, data, success, failed){
}
// 发送get请求
Ajax('get', url地址, post入参, function(data){
// 成功的回调逻辑
}, function(error){
// 失败的回调逻辑
})
这下两个请求库的名称不一样而且传递参数的方式也不同。但是了解适配器模式的小王瞬间想到了可以使用适配器模式来解决这个问题,于是他写出了一个适配器:
// Ajax适配器函数,入参与旧接口保持一致
async function AjaxAdapter(type, url, data, success, failed) {
const type = type.toUpperCase()
let result
try {
// 实际的请求全部由新接口发起
if(type === 'GET') {
result = await HttpUtils.get(url) || {}
} else if(type === 'POST') {
result = await HttpUtils.post(url, data) || {}
}
// 假设请求成功对应的状态码是1
result.statusCode === 1 && success ? success(result) : failed(result.statusCode)
} catch(error) {
// 捕捉网络错误
if(failed){
failed(error.statusCode);
}
}
}
// 用适配器适配旧的Ajax方法
async function Ajax(type, url, data, success, failed) {
await AjaxAdapter(type, url, data, success, failed)
}
可以发现适配器的特点。首先这个适配器的调用方式和原有的请求的调用方式是一样的,所以用户感知不到。而在适配器内部我们修改了网络请求的逻辑,里面使用的是小王自己封装的网络请求库的接口。这样,新旧接口之间就可以无缝衔接了。
适配器模式一个经典的生产应用就是Axios了,Axios一个令人惊喜的地方就是在浏览器和Node环境都能使用并且使用方式完全一致。这正是得益于Axios内部针对不同的环境采用不同的适配器,以及适配器的入参和返回结果都是完全一致的。也即适配器模式的精髓所在,用户无感知, 原来是怎么用的,现在还是怎么用,内部的变化不需要用户关心,也感知不到。
# 代理模式
通过第三方代理访问对象的方式被称为代理模式。
代理模式一个经典案例就是VPN。通过VPN访问网络时,实际上是访问到代理服务器,代理服务器请求真实服务器并将真实服务器返回的内容返回给客户端。这种看起来多此一举的操作可以绕过某些特殊的限制。
另一个在代码中的例子就是Proxy。通过new Proxy(target, handler)的方式可以创建某个目标对象的代理对象,借助代理对象可以对目标对象的访问和属性修改等操作进行拦截,或触发特定逻辑。在Vue3中,响应式的核心正是使用了Proxy。在生产实践中常用的几种代理模式有事件代理、虚拟代理、缓存代理和保护代理。
# 事件代理
事件代理一个经典的面试题:一个父元素包含多个子元素,希望每一个子元素在点击时触发相同事件,怎么做是最优解?答案就是事件代理,通过JS事件冒泡的特性,将需要触发的事件绑定到父元素而非子元素上,可以大大减少所需的事件监听器的数量,提高页面性能。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>事件代理</title>
</head>
<body>
<div id="father">
<a href="#">链接1号</a>
<a href="#">链接2号</a>
<a href="#">链接3号</a>
<a href="#">链接4号</a>
<a href="#">链接5号</a>
<a href="#">链接6号</a>
</div>
<script>
const father = document.getElementById('father')
father.addEventListener('click', function (event) {
if (event.target.tagName === 'A') {
event.preventDefault()
alert(`我是${event.target.innerText}`)
}
})
</script>
</body>
</html>
通过事件冒泡,将本应该由子元素触发的事件交给父元素进行代理处理。
# 虚拟代理
虚拟代理是一种用于优化对于昂贵资源的访问的设计模式,以图片预加载为例子,图片预加载技术会首先在目标位置加载一张占位图,然后在目标图片加载完毕之后,使用目标图片代替占位图片。在网络环境不好的情况下,预加载可以避免图片空位长期出现。
// 预加载类 用于获取图片节点同时替换图片src
class Preload {
constructor (imgNode) {
this.imgNode = imgNode
}
setSrc (imgUrl) {
this.imaNode.src = imgUrl
}
}
class ProxyImage {
static LOADING_URL = 'xxxxx'
constructor (targetImage) {
// targetImage是Preload的实例,是目标图片
this.targetImage = targetImage
}
setSrc (targetUrl) {
this.targetImage.setSrc(ProxyImage.LOADING_URL)
const virtualImage = new Image()
virtualImage.onload = function () {
this.targetImage.setSrc(targetUrl)
}
virtualImage.src = targetUrl
}
}
const imgNode = document.querySelector('#myImage'); // 获取真实的图片节点
const targetImage = new PreLoadImage(imgNode); // 创建 PreLoadImage 实例
const proxyImage = new ProxyImage(targetImage)
proxyImage.setSrc('目标图片url')
# 缓存代理
缓存代理也是一种性能优化模式。即在调用函数的使用,先根据参数查看是否已经存在过之前计算的结果。没有则计算并缓存结果,有则直接返回缓存结果。缓存代理是一种空间换时间的优化策略。在面试的时候遇到过这样的题目:闭包实现一个简单的缓存功能函数, 函数参数相同的情况下,返回上次参数相同时执行的结果。
function cacheFunction(fun, context) {
const cache = {}
context = context || this
return function (...args) {
const key = Array.prototype.join.call(args, ',')
if (key in cache) {
return cache[key]
}
return cache[key] = fun.apply(context, args)
}
}
# 保护代理
保护代理就是前文所说的Proxy。它可以对某一个对象的访问,属性修改,枚举等等操作进行拦截,从而达到保护的效果。在代理对象内部设置合理的逻辑,就能防止对于目标的恶意操作生效,是一种“保护”措施。
# 策略模式
在代码运行时,根据不同的情况选择不同的算法。
策略模式的两个重要原则。单一功能和开放封闭。单一功能指一个函数只处理一件事情,需要处理多个事情的情况下应考虑将函数进行拆分。开放封闭指对扩展开放,对修改封闭,新增加的功能应当是在原有代码的基础上扩展,而不是去修改源代码。
以电商网站打折为例。假设某一个商品在不同的情况下会打不同的折扣,一般的做法都是直接使条件判断语句直接在一个函数内部处理。
function price (type, originPrice) {
if (type === 'pre') {
return originPrice - 20
} else if (type === 'new') {
return originPrice * 0.5
} else if (type === 'onSale') {
return originPrice * 0.8
}
}
if-else的方式的确处理这种简单的情况没有问题,但是如果内部计算价格的逻辑稍微复杂一些,就会导致price函数的代码量不断增加,变得难以维护。并且price函数内部一下子就处理了三个逻辑,如果后续代码运行错误,非常难定位出现问题的代码。所以,更加明智的做法是将每个if-else中的逻辑封装为单个函数,根据类型的不同调用不同的函数。
// 将原有的价格计算逻辑封装到单个函数中
function price (type, originPrice) {
if (type === 'pre') {
return prePrice(originPrice)
} else if (type === 'new') {
return newPrice(originPrice)
} else if (type === 'onSale') {
return onSalePrice(originPrice)
}
}
上面的代码封装让每个函数的功能变得单一,price只根据不同的打折情况调用不同的价格计算函数。但是目前代码还是基于if-else编写,如果后续又有新的打折逻辑,需要不断的添加if-else并且每添加一次都需要将整个price函数进行重新测试。换言之,目前的代码的可扩展性非常差。那不用if-else怎么实现目前的功能呢?答案是对象映射。想一想,我们可以建立一个打折类型和价格计算函数之间的映射关系,当需要使用某个价格计算逻辑的时候,直接通过标签名进行定位就好了。
// 定义一个询价处理器对象
const priceProcessor = {
prePrice(originPrice) {
return originPrice - 20;
},
newPrice(originPrice) {
return originPrice * 0.5;
},
onSalePrice(originPrice) {
return originPrice * 0.8;
}
};
// price函数通过折扣类型调用价格计算函数
function price(type, originPrice) {
return priceProcessor[type](originPrice)
}
更加重要的是,后续如果有新的价格计算逻辑需要增加,直接在对象中添加新的映射关系即可,price函数和其他的价格计算逻辑完全不受任何影响。负责测试的同学也只需要测试这个新增加的逻辑而不需要对整个功能重新进行测试。
# 状态模式
根据对象状态的变化调整其行为的模式称为状态模式。
状态模式和策略模式乍看之下非常相似,都是根据不同条件调用不同的函数。区别在于这些被调用的函数是否具备感知主体的能力。以上文为例,策略模式中的函数可以脱离主体运行,无需感知主体信息。比如价格计算函数,只要给定一个初始价格就能计算出新的价格,主体如何它无法感知也不关心。但是状态模式中的行为函数不一样,它必须具备感知主体信息的能力。
采用状态模式的做法和策略模式基本一致,封装单一功能函数,建立对象映射关系。但是最后,需要将对象映射关系放到主体类中,使其成为主体类创建出的实例的一个属性。同时对象映射关系中还应该包含实例的信息。
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
// 初始化牛奶的存储量
this.leftMilk = '500ml';
}
stateToProcessor = {
// 此处的this指向类创建的实例
that: this,
american() {
// 以对象方法形式被调用,此处this指向stateToProcessor即调用方法的对象
console.log('咖啡机现在的牛奶存储量是:', this.that.leftMilk)
console.log('我只吐黑咖啡');
},
latte() {
this.american()
console.log('加点奶');
},
vanillaLatte() {
this.latte();
console.log('再加香草糖浆');
},
mocha() {
this.latte();
console.log('再加巧克力');
}
}
changeState(state) {
this.state = state;
if (!this.stateToProcessor[state]) {
return;
}
this.stateToProcessor[state]();
}
}
const mk = new CoffeeMaker();
mk.changeState('latte');
处于对象映射关系中的函数,在这里也被称为行为函数,可以通过this.that的方式访问到实例,进而获取到实例相关的信息。这在策略模式中则是不存在的。
# 观察者模式
观察者模式的核心在于建立一个一对多的关系,一个发布者和多个观察者。发布者发布新消息后通知所有订阅者,订阅者执行更新逻辑。
class Pulisher {
constructor() {
this.observers = []
}
add(observer) {
this.observers.push(observer)
}
remove(observer) {
this.observer.forEach((item, i) => {
if (item === observer) {
this.observers.splice(i, 1)
}
})
}
notify() {
this.onservers.forEach(observer => {
observer.update()
})
}
}
class Watcher {
constructor() {
}
update() {
}
}
观察者模式在生产模式一个非常经典的应用就是Vue2的响应式原理。每个组件都有一个Watcher实例,当组件进行渲染时,会被组件使用到的数据作为依赖进行收集,后续当某个依赖发生变化时,Watcher会重新计算并更新视图以实现响应式。简化版本的代码实现思路如下:
function observe(target) {
if (target && typeof target === 'object') {
Object.keys(target).forEach((key) => {
defineReactive(target, key, target[key])
})
}
}
function defineReactive(target, key, val) {
const dep = new Dep()
// 值为对象的属性递归遍历
observe(val)
Object.defineProperty(target, key, {
get() {
return val
},
set(value) {
target[key] = value
dep.notify()
}
})
}
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
this.subs.push(sub)
}
notify() {
this.subs.forEach((sub) => {
sub.update()
})
}
}
观察者模式的另一个重要应用就是事件总线。在学习Vuex这种全局状态管理工具之前,相信大家都或多或少听过事件总线,有了它就能够实现项目中任意两个组件之间的通信。下面实现的这个事件总线在面试中还有一个更加耳熟能详的名字:发布订阅模式。
发布订阅模式和观察者模式的不同在于发布者和观察者是否直接接触。 观察者模式中,发布者实例上会有一个记录所有订阅者的属性,当发布新消息时,发布者会直接通知所有的订阅者。而发布订阅模式中,包含一个事件中心handlers,这个事件中心可以理解为一个对象,其key是事件的名称,value则是事件被触发时需要调用的回调函数。
class EventBus {
constructor() {
this.handlers = {}
}
// 监听事件方法
on(eventName, cb) {
if (!this.handlers[eventName]) {
this.handlers[eventName] = []
}
this.handlers[eventName].push(cb)
}
// 触发事件方法
emit(eventName, ...args) {
if (this.handlers[eventName]) {
const handler = this.handlers[eventName].slice()
handler.forEach((callback) => {
callback(...args)
})
}
}
// 取消事件订阅,即删除某一个事件中的特定回调函数
off(eventName, cb) {
const callbacks = this.handlers[eventName]
const index = callbacks.indexOf(cb)
if (index !== -1) {
callbacks.splice(index, 1)
}
}
// 注册单次事件监听器
once(eventName, cb) {
// 将原始回调函数包装,触发一次之后就取消
const wrapper = (...args) => {
cb(...args)
this.off(eventName, wrapper)
}
this.on(eventName, wrapper)
}
}
上述发布订阅模式实现的4种方法是最常用的方法,务必牢记其实现,特别是once方法的包装方法。
# 迭代器模式
迭代器模式提供一种顺序访问聚合对象内部各个元素的方法,而又不暴露对象的内部结构。
迭代器其实在JS中以及有了内置的实现,就是for...of...方法,这个方法可以帮助我们实现各个类型数据的遍历,包括类数组。实际上我们自己也可以实现一个迭代器。
function iteratorGenerator(list) {
var index = 0
var length = list.length
return {
next() {
var done = index >= length
var value = !done ? list[index++] : undefined
return {
done,
value
}
}
}
}
var iterator = iteratorGenerator(['1号选手', '2号选手', '3号选手'])
iterator.next()
iterator.next()
iterator.next()
迭代器生成函数的本质是返回一个包含next()方法的对象,next()方法返回一个包含done value两个属性的对象。done表示是否完成遍历,由当前遍历到的元素的索引和对象总长度1比较得来,value则表示当前遍历到的元素的值。
# 总结